Redis数据结构
String
其value为字符串,根据字符串的格式不同,可以分为3类:
- string:普通字符串
- int:整数类型,可以做自增、自减操作
- float:浮点类型,可以做自增、自减操作
不管哪种格式,底层都是字节数组形式存储,只不过编码方式不同。字符串类型的最大空间不超过512M。

String类型常见命令:
- SET、GET、MSET、MGET
- INCR:让一个整型的key自增1
- INCRBY:让一个整型的key自增指定步长
- INCRBYFLOAT:让一个浮点类型的数字自增指定步长
- SETNX:添加一个String类型的键值对,前提是这个key不存在,否则不执行
- SETEX:添加一个String类型的键值对,并且指定有效期
项目中的应用:
- 以 前缀“phone:“ + 手机号码 为key,存储验证码。
- 可以将java对象序列化为JSON字符串,然后存储到string中。
- 利用INCR命令实现全局唯一ID。
Hash
hash类型,也叫散列,其value是一个无序字典,类似于hashmap结构。
如果使用string存储对象,当需要修改对象某个字段时很不方便,而hash结构可以将对象中的每个字段独立存储,可以针对单个字段做CRUD。

Hash类型常见命令:
- HSET key field value:添加或修改field的值
- HGET
- HMSET、HMGET
- HGETALL key:一次性获取key中的所有field和value
- HKEYS:获取所有field
- HVALS:获取所有value
- HINCYBY
- HSETNX:添加一个hash类型的key的filed值,前提是这个field不存在,否则不执行
项目中的应用:
- 存储用户信息
1 | Map<String, Object> userMap = BeanUtil.beanToMap(userDTO, new HashMap<>(), |
List
Set
SortedSet
Redis的SortedSet是一个可排序的set集合,里面的每一个元素都带有一个score属性,可以基于score属性对元素排序,其底层的实现是一个跳表(SkipList)+ hash表。
sortedset具有以下特性:
- 可排序
- 元素不重复
- 查询速度快
常见命令:
- ZADD key score member:添加一个或多个元素到sortedset,如果已经存在则更新其score
- ZREM key member:删除一个指定元素
- ZSCORE key member:获取指定元素的score
- ZRANK key member:获取指定元素的排名
- ZCARD key:获取sortedset中的元素个数
- ZCOUNT key min max:统计score值在给定范围内的所有元素的个数
- ZINCRBY key increment member:让指定元素自增
- ZRANGE key min max:按score排序后,获取指定排名范围内的元素
- ZRANGEBYSCORE key min max:按score排序后,获取指定score范围内的元素
- ZDIFF、ZINTER、ZUNION:求差集、交集、并集
在项目中应用:
点赞排行榜:为每个博客维护一个sortedset,记录所有点过赞的用户,并用score来存时间戳。这样按照score排序,就能按照时间先后顺序排序。
Feed流的滚动分页:由于Feed流中的数据会不断更新,导致数据的角标也在变化,因此不能采用穿透的分页模式,只能采用滚动分页。为达到效果,使用redis中的sortedset数据结构来存储消息和时间戳,分页查询时,从上次查询的最小时间戳开始查。
![image-20250221192829761]()

Geo
Geo即Geolocation的简写,代表地理坐标,Redis在3.2版本加入了对GEO的支持。
Geo常用命令:
- GEOADD:添加一个地理空间信息,包含:经度(longitude)、维度(latitude)、值(member)
- GEODIST:计算指定的两个点之间的距离并返回
- GEOHASH:将指定member的坐标转为hash字符串形式并返回
- GEOPOS:返回指定member的坐标
- GEORADIUS:指定圆心、半径,找到该圆内的所有member,并按距离排序返回。6.2后废弃
- GEOSEARCH:在指定范围内搜索member,并按距离排序返回。范围可以是圆形或矩形。6.2新功能
- GEOSEARCHSTORE:与GEOSEARCH功能一致,不过可以把结果存储到一个指定的key中。6.2新功能
在项目中应用:
- 附近商户功能:使用Geo来存储商户地理信息,并应用GEOSEARCH来查找附近商户。
BitMap
Redis中利用string类型数据结构实现Bitmap,最大上限为512M,即2^32个bit位。
BitMap的命令:
SETBIT:向指定位置(offset)存入一个0或1
GETBIT:获取指定位置(offset)的bit值
BITCOUNT:统计BitMap中值为1的bit位的数量
BITFIELD:操作(查询、修改、自增)BitMap中的指定位置(offset)的值
BITFIELD_RO:获取BitMap中的bit数组,并以十进制返回
BITOP:将多个BitMap的结果做位运算(与、或、异或)
BITOPS:查找bit数组中指定范围内第一个0或1出现的位置
项目中应用:
- 可以用BitMap实现用户签到功能,用“前缀 + 用户id + 年月”作为key,存储用户每一个月的签到结果。把每一个bit位对应当月的每一天,用户签到则将对应那一日的bit为设置为1。

HyperLogLog
Hypeloglog(HLL)是从Loglog算法派生的概率算法,用以确认非常大的集合的基数,而不需要存储其所有值。
Redis中的HLL是基于string结构实现的,单个HLL的内存永远小于16kb。作为代价,其测量结果是概率性的,有小于0.81%的误差,但对于UV统计来说,是可以忽略的。
HyperLogLog命令:
- PFADD key element [element …]:向指定key添加一个元素
- PFCOUNT key:统计指定key中元素个数(基于概率的)
- PFMERGE destkey sourcekey 合并两个key
应用:
- UV统计
UV:Unique Visitor,独立访客量,指通过互联网访问网页的自然人,1天内同一个用户多次访问网站,只记录1次。
PV:Page View,页面访问量或点击量,用户每访问网页的一个页面,记录一次PV,多次打开则多次记录PV。往往用来衡量网站的流量。
UV统计在服务端做比较麻烦,因为要判断该用户是否已经统计过了,需要将统计过的用户信息保存。但如果每个访问的用户都保存到Redis中,数据量会非常恐怖。
登录注册
验证码登录
使用session进行登录存在session共享问题:多台Tomcat并不共享session存储空间,当切换到不同tomcat服务时会导致数据丢失。因此基于redis实现共享session登录。
客户端根据收到的验证码填入并登录,服务端收到请求之后,从Redis中校验验证码和手机号是否匹配,如果匹配就成功登录,则将用户的信息保存到Redis中,并返回随机token给客户端;客户端后续请求都带着这个token在作为autorization放在请求头里面。

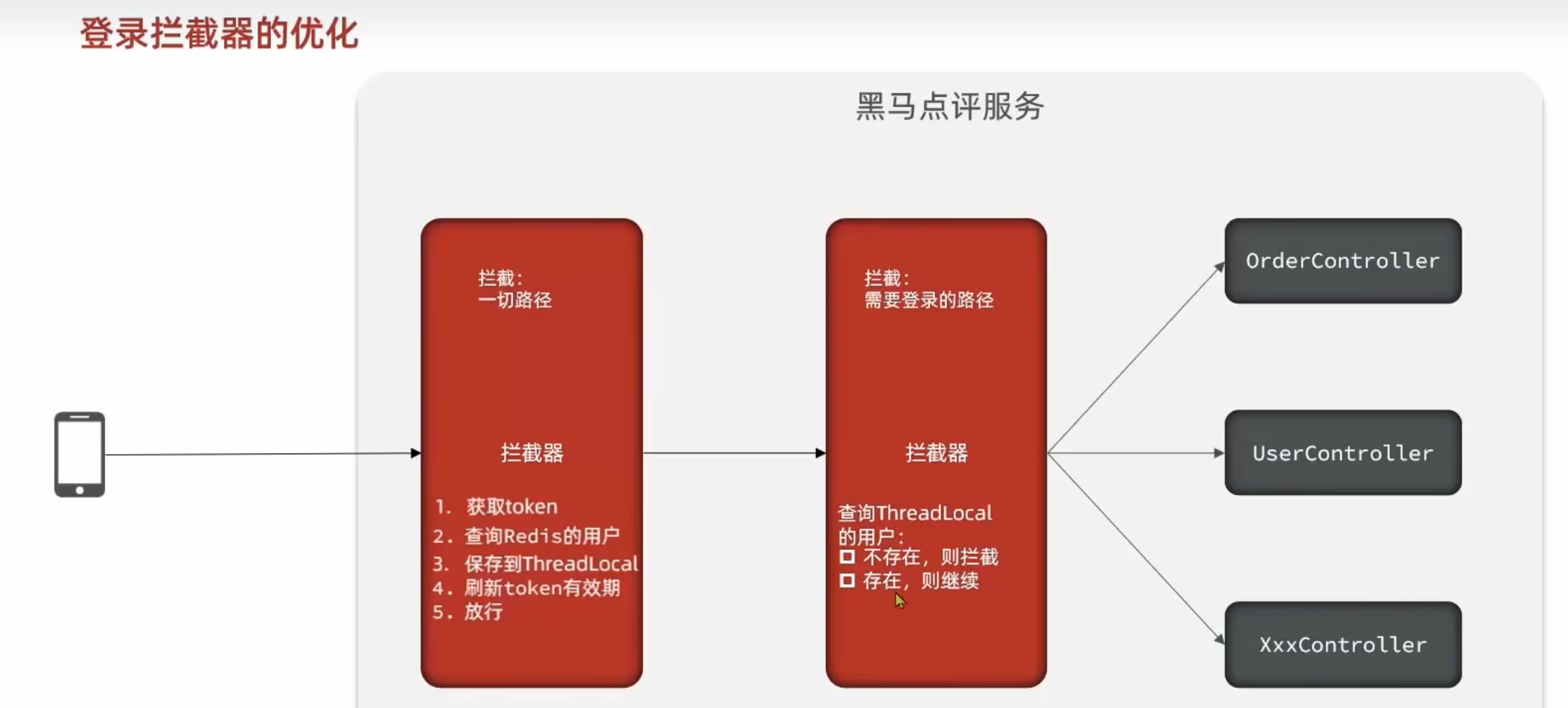
登录拦截器
登录拦截器设置成两个拦截器,第一个拦截器拦截一切路径,进行获取token、查询redis用户、保存到ThreadLocal和刷新token有效期,而第二个拦截器才拦截需要登录的路径,查询ThreadLocal中的用户是否不存在,不存在则拦截。
这样所有路径都可以刷新token有效期,也就是用户点击任何页面都能刷新登录状态。
商户查询缓存
缓存就是数据交换的缓冲区(cache),存贮数据的临时地方,一般读写性能较高。
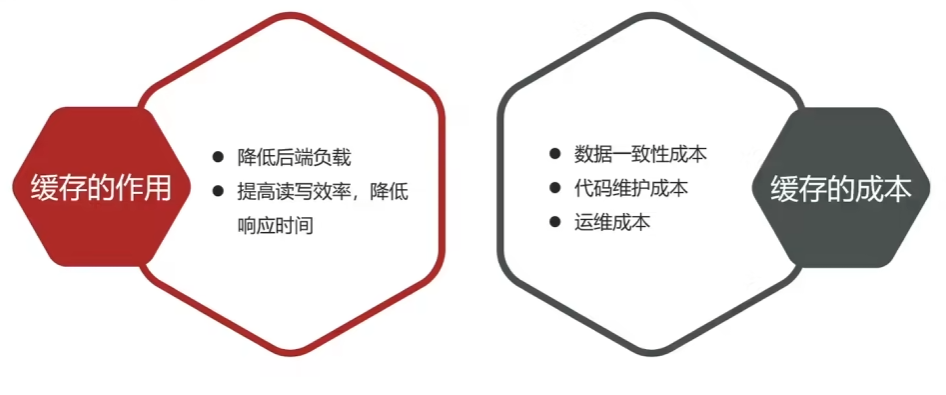
缓存更新策略
缓存更新策略
| 内存淘汰 | 超时剔除 | 主动更新 | |
|---|---|---|---|
| 说明 | 不用自己维护,利用Redis的内存淘汰机制,当内存不足时自动淘汰部分数据,当内存不足时自动淘汰部分数据。下次查询时更新缓存。 | 给缓存数据添加TTL时间,到期后自动删除缓存。下次查询时更新缓存。 | 编写业务逻辑,在修改数据库的同时,更新缓存。 |
| 一致性 | 差 | 一般 | 好 |
| 维护成本 | 无 | 低 | 高 |
业务场景:
- 低一致性需求:使用内存淘汰机制。例如店铺类型的缓存。
- 高一致性需求:主动更新, 并以超时剔除作为兜底方案。例如店铺详情的缓存。
主动更新策略
| Cache Aside Pattern | Read/Write Through Pattern | Write Behind Caching Pattern |
|---|---|---|
| 由缓存的调用者,在更新数据库的同时更新缓存。 | 缓存与数据库整合为一个服务,由服务来维护一致性。调用者调用该服务,无需关心缓存一致性问题。 | 调用者只操作缓存,由其他线程异步的将缓存数据持久化到数据库,保证最终一致。 |
| 调用者需要写一些代码 | 维护一个这样的服务复杂,成本高 | 效率高,但维护异步服务难,可靠性和一致性较差 |
采用Cache Aside Pattern。
如何操作数据库和缓存
删除缓存还是更新缓存?
- 更新缓存:每次更新数据库都更新缓存,无效写操作较多。
- 删除缓存:更新数据库时让缓存失效,查询时在更新缓存。√
如何保证缓存与数据库的操作的同时成功或失败?
- 单体系统:将缓存与数据库操作放在一个事务。
- 分布式系统:利用TCC等分布式事务方案。
先操作缓存还是先操作数据库?(线程安全问题)
![image-20250215150429038]()
- 由于更新数据库操作比较缓慢,而查询数据库和写入缓存操作很快,线程2很容易趁虚而入,因此该情况发生概率高。
![image-20250215150750330]()
发生该情况需要满足:1.两个线程并行;2.缓存恰好失效;3.在线程1查询缓存和写入缓存两个操作的微秒级空隙内,线程2完成更新数据库和删除缓存操作。因此该情况发生的概率很低。
因此先操作数据库再删除缓存。


缓存更新策略的最佳实践方案
- 低一致性需求:使用Redis自带的内存淘汰机制
- 高一致性需求:主动更新, 并以超时剔除作为兜底方案
- 读操作:
- 缓存命中则直接返回
- 缓存未命中则查询数据库,并写入缓存,设定超时时间
- 写操作
- 先写数据库,然后再删除缓存
- 要确保数据库与缓存事务的原子性
- 读操作:
缓存穿透
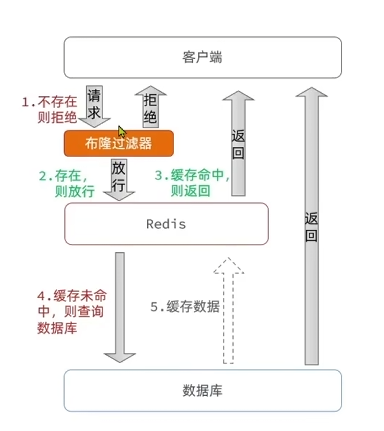
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。例如,一个不怀好意的黑客同时间内大量请求不存在的数据,这些请求都会打到数据库上,导致数据库崩溃。
常见的解决方案有两种:缓存空对象和布隆过滤。
其他解决方案:增强id的复杂度,避免被猜测id规律;做好数据的基础格式校验;加强用户权限校验;做好热点参数的限流。
缓存空对象
查询时发现数据在数据库中不存在,则在redis中缓存一个空对象并设置过期时间。这样以后查询的数据不存在时,会命中缓存。
- 优点:实现简单,维护方便
- 缺点:
- 额外的内存消耗(解决:设置TTL)
- 可能造成短期的不一致(例如,用户查询不存在得数据,缓存设置未null,此时数据库更新,用户再次查询仍然为null)(可以在新增数据时插入缓存,覆盖null)
布隆过滤
添加一个布隆过滤器,用来判断数据是否存在。查询缓存前需经过过滤器。
Redis中布隆过滤器底层为一个大型位数组(二进制数组)+多个无偏hash函数
优点:内存占用较少,没有多余key
缺点:
- 实现复杂
- 存在误判可能(可能有数据不存在但放行的情况)
缓存雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案:
- 给不同的Key的TTL添加随机值,用以预防同一时段大量的缓存key同时失效
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
缓存击穿
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问在瞬间给数据库带来巨大的冲击。
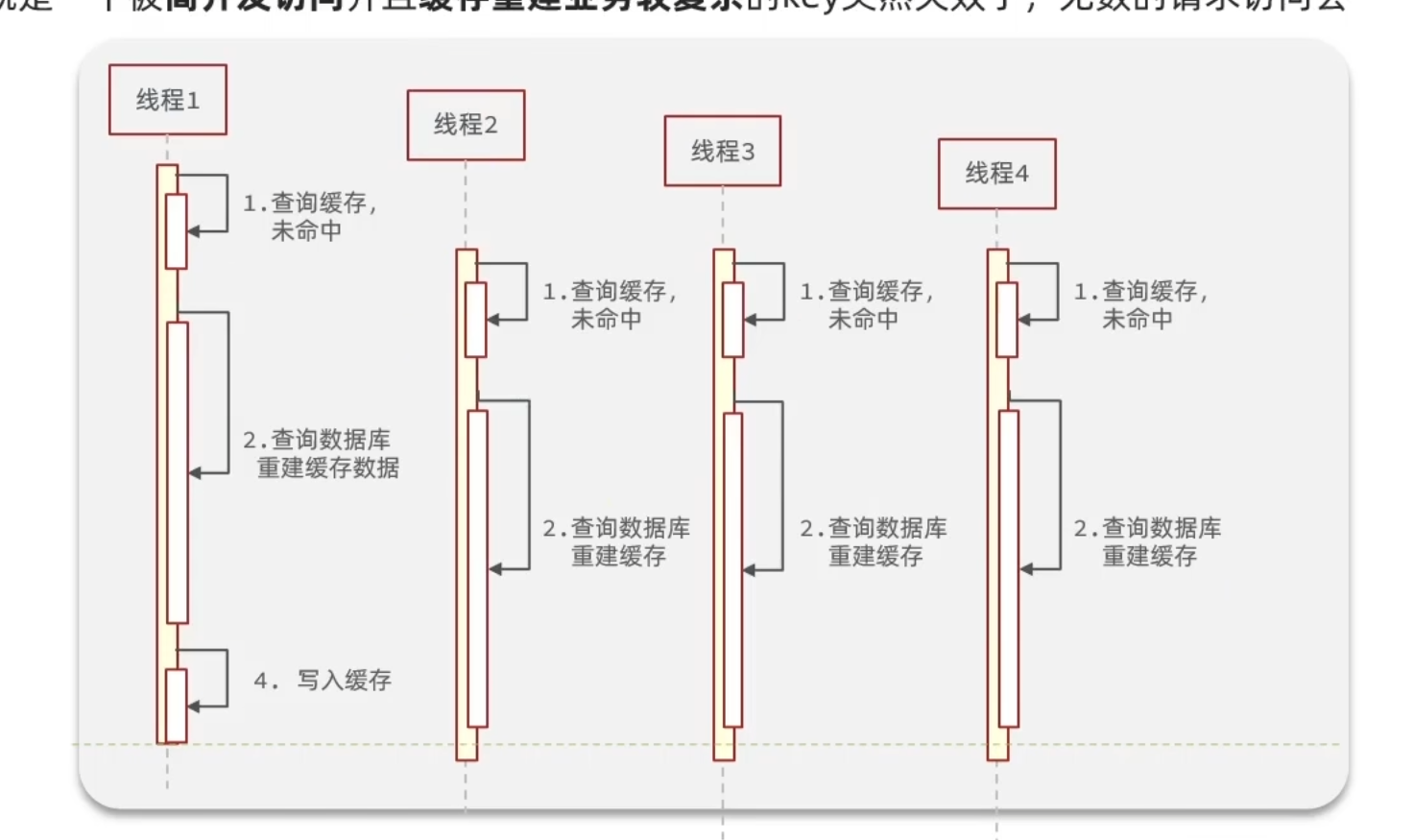
解决:互斥锁或逻辑过期。
互斥锁
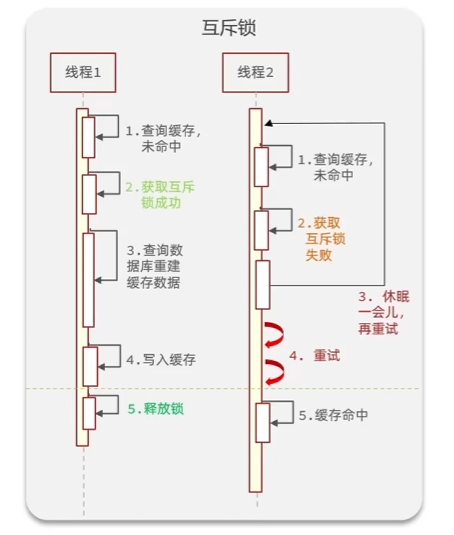
线程A发现缓存过期,加锁重建缓存,后续线程阻塞直至线程A释放锁,此时缓存重建成功。
优点:
- 没有额外的内存消耗
- 保证一致性
- 实现简单
缺点:
- 线程需要等待,性能受影响
- 可能有死锁风险
逻辑过期
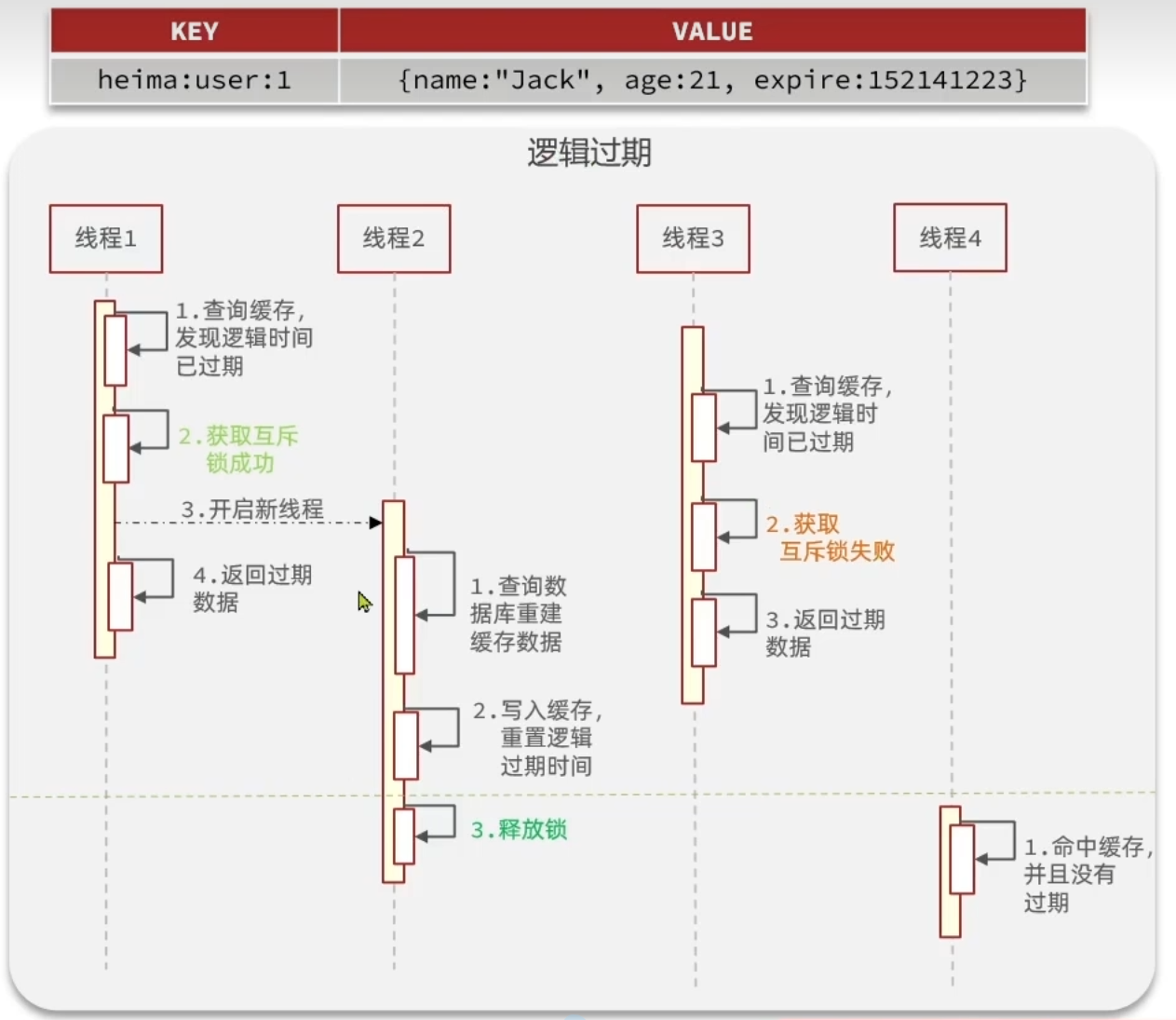
不设置过期时间,但在value中添加逻辑过期字段,线程A查询热点key发现value中逻辑时间过期,则线程A加锁并另起线程B重建缓存,线程A直接返回旧数据(不需等待线程B执行结束),后续线程C查询缓存发现过期后尝试加锁,如果加锁失败则说明有线程正在重建缓存,线程C也直接返回旧数据即可。
优点:
- 线程无需等待,性能较好
缺点:
- 不保证一致性
- 有额外内存消耗
- 实现复杂
优惠券秒杀
全局唯一id
对于优惠券订单,如果使用数据库自增ID会存在以下问题:
- id的规律性太明显
- 受单表数据量的限制
因此需要一种在分布式系统下用来生成全局唯一ID的生成器。
解决方案:利用Redis中String结构的自增INCR命令。

其他全局唯一ID生成策略:
- UUID
- snowflake雪花算法
- 数据库自增
超卖问题
超卖问题
在并发情况下,可能出现类似下图的情况,此时会出现商品超卖问题。
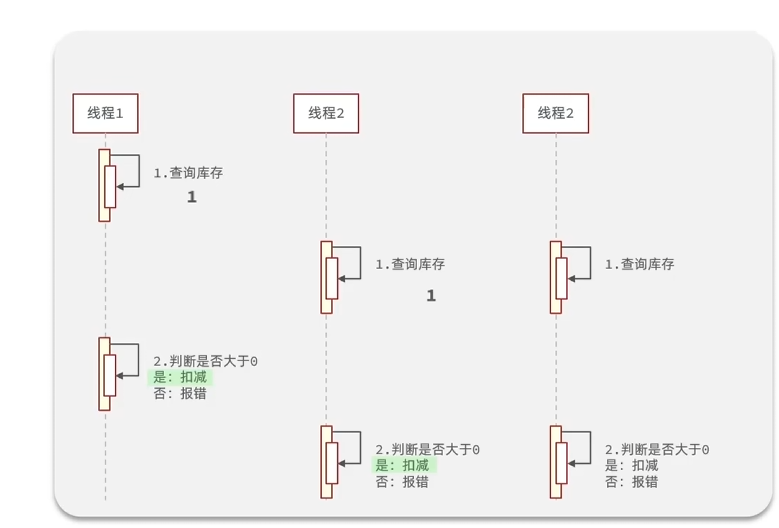
为了解决这种情况,就需要加锁,锁有悲观锁和乐观锁两种。
悲观锁:
- 认为线程安全问题一定会发生,因此在操作数据之前先获取锁,确保线程串行执行。
- 例如Synchronized、Lock都属于悲观锁。
乐观锁:
- 认为线程安全问题不一定会发生,因此不加锁,只是在更新数据时去判断有没有其他线程对数据做了修改。
- 如果没有修改则认为是安全的,自己才更新数据。
- 如果已经被其他线程修改说明发生了安全问题,此时可以重试或异常。
在优惠券秒杀中,使用悲观锁使得线程串行执行,性能较差,因此使用乐观锁。
两种乐观锁
版本号法:给数据加上一个版本,每一次修改数据变化一次版本,多线程并发情况下,基于版本号来判断数据是否被修改过。
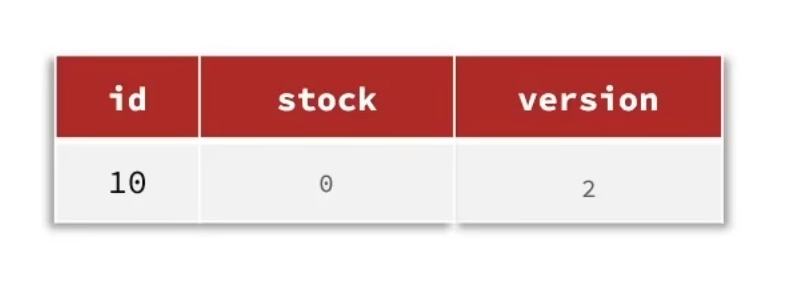
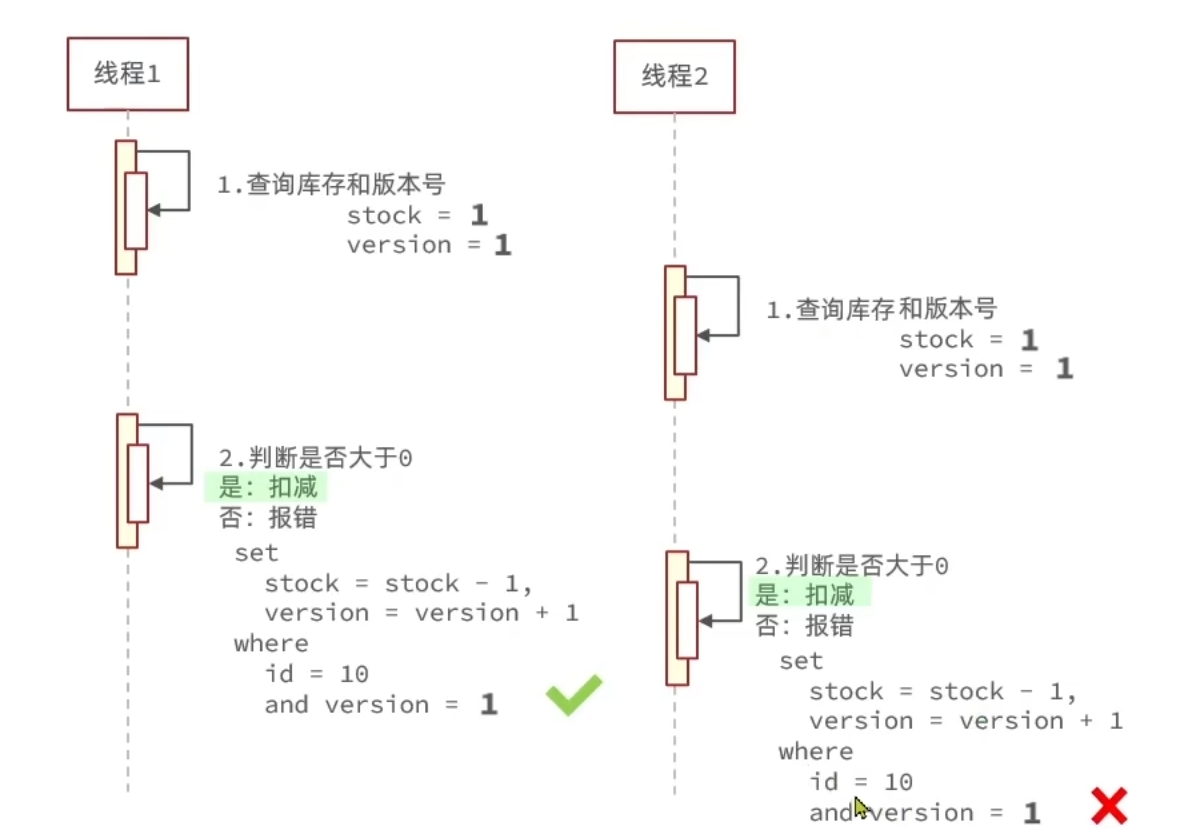
CAS法(Compare and SET):用数据本身是否变化来作为版本,即每次修改数据前,判断数据是否与修改前一致。
1 | boolean success = seckillVoucherService.update() |
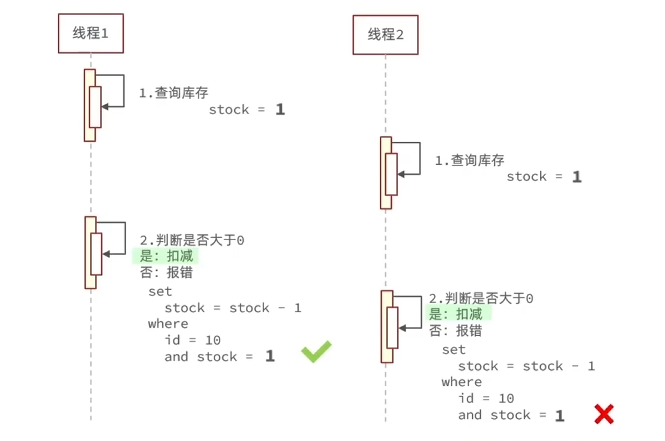
但这种情况下,可能出现失败率高的问题,即多个线程同时尝试,只有一个成功。
可以做个简单的改进,直接判断更新数据时库存是否大于0。
1 | boolean success = seckillVoucherService.update() |
一人一单问题与分布式锁
对于同一张优惠券,可能出现一个用户购买多次情况,为阻止这种情况,需要实现一人一单。
直接判断用户是否下过订单,在并发情况下仍然会出现问题(即一个人同一时刻购买多次),简单的想法是给userId加一个synchronized锁。注意,给userId加synchronized锁时,要写成下面这种。这是由于toString()返回的是一个新的string对象,而我们需要的是判断值是否一样,因此调用intern方法。
1 | synchronized (userId.toString().intern()) {...} |
此外,假如我们给创建订单createVoucherOrder方法加了@Transcational事务注解,那么synchronized锁应该加在方法外面。如果加在里面,可能会出现事务还未提交,锁就被释放,其他线程趁虚而入而数据库还未更新的情况。
使用synchronized锁,在集群部署情况下(多个tomcat),仍然会出现并发安全问题,不同jvm下的线程无法实现锁互斥,如下:

因此需要采用一种集群模式下多进程可见的分布式锁。常见的三种分布式锁:

Redis分布式锁
利用redis的SETNX命令可以实现一个满足互斥锁;同时设置EX过期时间,保证故障时锁依然能被释放,避免死锁。
获取锁:
1 | SET lock thread1 NX EX 10 |
释放锁
1 | DEL key |

这种实现可能出现这样的安全问题:当线程1某种原因阻塞时,超时释放锁,其他线程获取锁后,线程1恢复后可能会释放其他线程获取的锁。

为了解决该问题,为了解决该问题,在释放锁时应该判断是否是自己的锁,只有是自己的锁才允许释放。

但这时仍然有可能出现问题,如下图,当线程1获取锁标识并判断一致后,还未释放锁时遇到阻塞(如jvm垃圾回收),导致后面又释放了其他线程的锁。

因此必须确保判断锁标识动作和释放锁动作的原子性,可以使用Lua脚本。
Redis的Lua脚本
Redis提供了Lua脚本功能,在一个脚本中编写多条Redis命令,确保多条命令执行时的原子性。
1 | -- 获取锁中的线程标识 get key |
Redisson
基于Redis实现的分布式锁有以下问题:
- 不可重入:同一个线程无法多次获取同一把锁。
- 不可重试:获取锁只尝试一次就返回false,没有重试机制。
- 超时释放:锁超时释放虽然可恶意避免死锁,但如果是业务执行耗时较长,也会导致锁释放,存在安全隐患。
- 主从一致性:如果Redis提供了主从集群 ,主从同步存在延迟,当主节点宕机时,如果从节点尚未同步主节点中的锁数据,则会出现锁丢失。
因此使用Redisson来优化。Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现。
Redisson原理:
可重入
可重入锁:同一个线程多次请求锁,可能会造成死锁。因此需要允许可重入锁。
利用redis中的hash数据结构,为锁额外记录一个值,代表该锁的重入次数。

同一个线程每重入一次锁,将值+1,释放锁改为将值-1,值为0时才真正释放锁。

为保证原子性,同样要使用Lua脚本。
重试机制与超时续约
redisson可以设置等待时间waitTime,在获取锁失败后,会订阅并等待释放锁的信号,然后进行重试,直到获取锁成功或waitTime消耗完。
redisson中的watchdog在获取锁时设置了一个定时任务,每隔一段时间刷新锁的有效期(releaseTime/3),直到释放锁时取消定时任务。注意,如果设置了leaseTime就没有watchdog了。

主从一致性问题
问题产生原因:

redisson解决方案:MultiLock
将每一个redis节点都视为主节点,只有向每个节点获取锁成功,才算成功。此时如果一个redis节点宕机,并不影响锁的正常获取和释放。此外也可以给每个节点建立主从关系,此时如果一个主节点宕机且刚好没有完成同步,由于从节点没有锁的标识,其他线程也无法成功获取锁,满足要求。


异步秒杀
原理
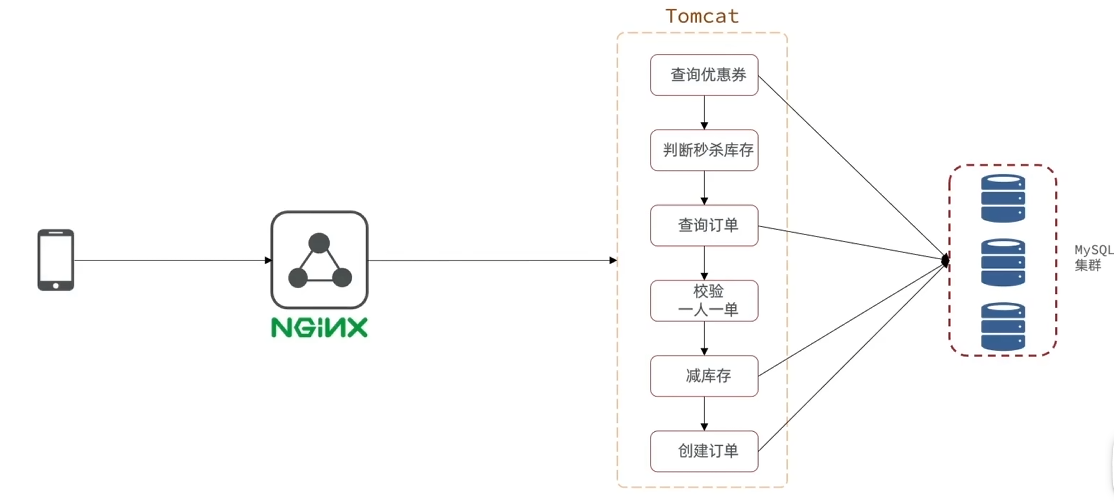
上图是秒杀业务的部署图,按照顺序进行每个步骤,耗时为所有步骤之和,其中一些业务还需要访问mysql,导致整个流程缓慢,效率低。因此需要用到异步秒杀。
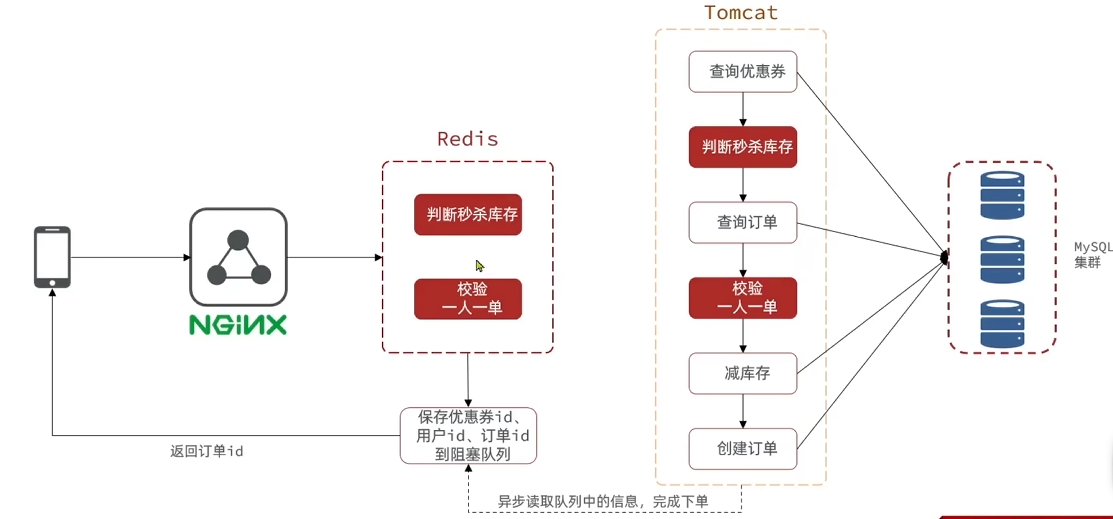
可以采用异步执行的方式来进行优化整个流程,即开启新的线程去执行比较耗时的操作。
将判断库存与校验一人一单的工作让redis执行,如果符合条件,添加订单到阻塞队列,让异步程序再执行。
库存判断使用redis的string数据结构即可,而一人一单则使用set数据结构。同样,为保证redis业务的原子性,使用lua脚本。
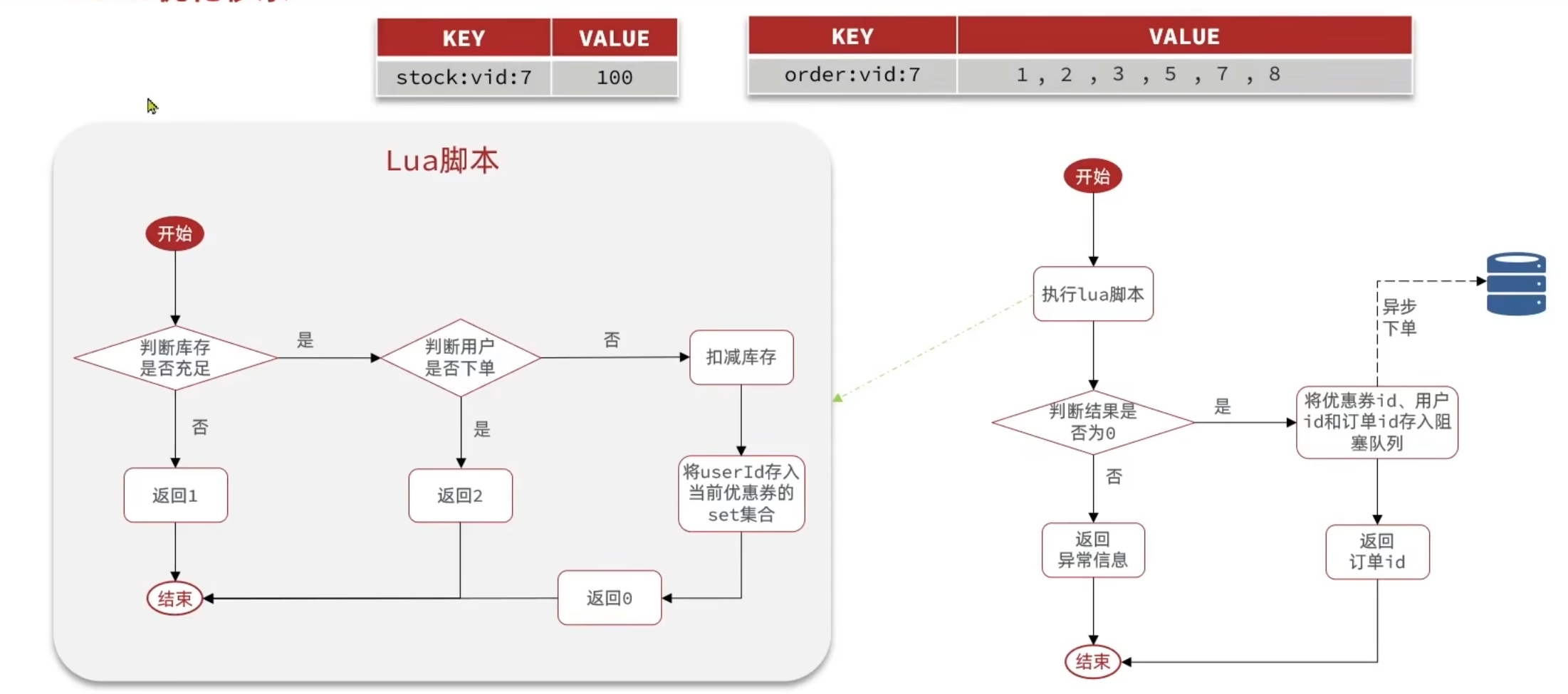
但是基于阻塞队列的异步秒杀存在以下两问题:
- 内存限制问题:使用jdk的阻塞队列会消耗jvm内存,在高并发情况下可能导致内存溢出。而如果设置队列上限会导致超出的订单无法添加。
- 数据安全问题:如果服务宕机,会导致内存中的订单信息丢失。如用户下单付款后,但后台并没有订单数据,出现数据不一致情况。或者异步任务从队列中取出任务执行时,服务崩溃,那么任务就会丢失。